Vous n'êtes pas identifié(e).
Le rapport Villani publié le 28 mars 2018, sur l'intelligence artificielle :
https://www.aiforhumanity.fr/
Fichier *pdf (230 pages) : https://www.aiforhumanity.fr/pdfs/9782111457089_Rapport_Villani_accessible.pdf
Dernière modification par alex20 (29/03/2018 21:29)
Hors ligne
29 Mars 2018
Et dans la foulée :
1. La stratégie française en faveur de l'IA : 1,5 milliard d'euros pour développer l'intelligence artificielle :
https://www.lesechos.fr/tech-medias/hightech/0301499826147-macron-annonce-15-milliard-deuros-pour-developper-lintelligence-artificielle-2165288.php
2. Microsoft investit 30 millions de dollars dans l'IA française et promet 3 000 embauches :
http://mashable.france24.com/tech-business/20180329-microsoft-30-millions-intelligence-artificielle-france
3. IBM va recruter 400 experts en France :
https://fr.news.yahoo.com/intelligence-artificielle-annonces-pleuvent-ibm-180604451.html
Hors ligne

L'IA arrive doucement.... dans nos avions on a déjà vu le bouleversement radical qu'à apporté l'informatique avec la génération "A320" par rapport à la génération précédente, il faut s'attendre au même saut lorsque l'IA pointera le bout de son nez dans les cockpits.
Dernière modification par Bee Gee (30/03/2018 11:42)
"On n'est pas des ... quand même !" Serge Papagalli,
Hors ligne

archnophobe s'abstenir..=8

Hors ligne
N'est pas médaille Fields qui veut..
J'adore ce genre de personnage atypique, toujours très intéressant à écouter dans ses conférences, bien plus que le blabla stérile de trop nombreux pilotes !
Et puis quoiqu'on en dise, sans les matheux, nos avions ne voleraient pas aussi bien, et on en serait encore au cerf-volant.
"On n'est pas des ... quand même !" Serge Papagalli,
Hors ligne
L’IA est déjà présente dans beaucoup d’applications que nous utilisons sans le savoir (moteur de recherche internet, traduction automatique, reconnaissance vocale, détection de fraudes, prédictions économiques etc).
Dans mon domaine les algorithmes génétiques et réseaux de neurones sont utilisés depuis de nombreuses années mais avec la puissance des CPU actuels on arrive à traiter des quantités toujours plus importantes de données ce qui permet de faire ce qui était impensable il y a 10 ans.
Maintenant la vraie question à se poser est jusqu’où cela va aller car si les machines deviennent capables de rivaliser avec l’intelligence humaine le risque que nous, pauvres humains, perdions le contrôle à terme est bien réel et c’est d’ailleurs ce que prédisait feu S. Hawking...
Dernière modification par ydelta (30/03/2018 20:31)
PC: i9 9900K @5.2 Ghz - Gigabyte GEForce RTX 4080 OC 16 Go - Asus Z390 Pro Gaming - 32Go de RAM DDR4 3200
Portable: MSI Raider 18 HX - i9 14900HX RTX 4080 12Go 4K 18" display 240hz - 64Go DDR5 5200 - 3To M2 SSD
Hors ligne
30 mars 2018 - Sciences et Avenir
"L’éthique en intelligence artificielle, un sujet à part entière"
https://www.sciencesetavenir.fr/high-tech/intelligence-artificielle/rapport-villani-l-ethique-en-intelligence-artificielle-un-sujet-a-part-entiere_122589
Dernière modification par alex20 (31/03/2018 00:42)
Hors ligne

Maintenant la vraie question à se poser est jusqu’où cela va aller car si les machines deviennent capables de rivaliser avec l’intelligence humaine le risque que nous, pauvres humains, perdions le contrôle à terme est bien réel et c’est d’ailleurs ce que prédisait feu S. Hawking...
Elle dépasse déjà l'être humain dans certains domaines ( échecs, go ...), perso je suis quand même inquiet sur ce que ça va devenir , l'élève dépasse le maître
du moment qu'on maîtrise, ok, mais je ne suis pas sûr du résultat
Hors ligne
l'IA est évidemment utile pour la Science, - toujours ce principe fondamental: la Science et la technologie sont liées, l'un ne va pas sans l'autre - mais la Science n'a pas pour but de faire l"bonheur de l'humanité en lui permettant de faire plus de pognon"
ça, c'est le charlatanisme et la démagogie, qui sont la cause du malheur de l'humanité
comment l'IA pourrait-elle faire "le progrès et le bonheur de l'humanité" si les démagogues s'en emparent pour mieux abrutir les gens et imposer leur démagogie
pour mieux encourager les concitoyens conformes consommateurs à mieux consommer aveuglément sous prétéexte que l'l'IA va s'occuper de penser à leur place pour "résoudre les pbs"...!?
faut être un peu logique..;
c'est l'intelligence humaine, pas artificielle, qui peut résoudre les pbs
mais là, évidemment, c'est plus difficile, le pognon ne rend pas spécialement "intelligent", bien au contraire......=O
pour Villani, lui-même sait bien qu'il a une araignée sous le plafond, il s'en amuse d'ailleurs, ça ne le gêne pas du tout, bien au contraire, c'est elle qui lui permet d'avoir sa belle médaille, notamment
c'est bien pour ça qu'il l'affiche...=8
juste que ça lui fait prendre un peu la grosse tête, il ne faisait pas tout ce cinéma avant
mais pas d'importance, s'il s'amuse ...
ça ne gêne personne
juste pour noter que sa vision "politique" de l'IA n'est que démagogie...
rien à voir avec son "génie"de mathématique
la France est un nain / aux US et Chine, il faut un big data que la France et même l'EU n'ont pas, loin de là
mais encore une fois, aucune importance, la science n'a pas de frontières
par contre, IA + démagogie, là, on peut craindre le pire...
Hors ligne

Bonjour a tous...
sujet aussi interessant qu'inquietant ....
Personnellement je trouve ce sujet inquietant depuis que l'IA est capable d'auto aprentissage....
Google a un projet nommé "Brain" actif depuis 2011...
https://fr.wikipedia.org/wiki/Google_Brain
Comme le disait YDelta Certaines avancées sur ce projet sont d'ores et deja utilisées a l'echelle du web...
dernierement l'equipe de google a mis au point une IA nommé "AutoML" (Automatic Machine Learning)
http://sciencepost.fr/2017/12/lintelligence-artificielle-de-google-a-cree-propre-i-a-celle-surpasse-celle-de-lhomme/
Il s'agit de la generation D' une IA avancée (A priori Superieure sur certains points au moins a l'intelligence humaine).... par une autre IA...
Quand je vois
-les evolutions dans ce domaine,
-les evolutions de la capacité de calcul des processeurs en general,
- les avancées au niveau des ordinateurs "quantique",
-les evolutions faites au niveau de la cybernetique militaire par toutes les grandes puissances (Voir par ex "Boston Dynamics" aux US...mais il y en a d'autres )....
https://www.cnbc.com/2017/11/16/boston-dynamics-atlas-robot-can-now-do-a-backflip.html
-Les "evolutions" en terme de surveillance des reseaux et des populations....(Deep Packet Inspection au niveau des Routeurs des FAI, reconnaissance faciale, comportementale, sur fichiers image et video par des algorithmes specifiques...)
Et quand je vois nos politiques,....je suis pas franchement rassuré pour l'avenir de nos gosses...
Un raccourci peut etre simpliste et j'espere alarmiste...
mais...Si "Big Brother" est deja largement en place (tout au moins techniquement) voire depassé depuis des lustres ... "Terminator" semble bien maintenant du domaine du possible...
@Pluche
edit:
Maintenant la vraie question à se poser est jusqu’où cela va aller car si les machines deviennent capables de rivaliser avec l’intelligence humaine le risque que nous, pauvres humains, perdions le contrôle à terme est bien réel et c’est d’ailleurs ce que prédisait feu S. Hawking...
Entierement d'accord...on peut se poser la question du comportement qu'aura une "entité" superieurement intelligente, si elle en arrive a considerer l'humain comme une menace potentielle....
Dernière modification par Wind_D4ncer (31/03/2018 15:15)
Ils ne savaient pas que c'etait impossible... Alors ils l'ont fait...
Hors ligne
Bonjour à tous,
Si vous avez quelques minutes disponibles pour lire mon poste, je voudrais vous exposer
aussi un aspect très intéressant et même révolutionnaire sur le développement actuel des
certains programmes IA capables d'auto apprentissage.
AlphaGo Zero - AlphaGo est un programme informatique, capable de jouer au jeu de go et aux échecs,
développé par l'entreprise britannique DeepMind Technologies (actuelement Google DeepMind)
elle est rachetée le 26 janvier 2014, par Google pour plus de 628 millions de dollars américains.
L'algorithme d'AlphaGo combine des techniques d'apprentissage automatique et de parcours de graphe,
associées à de nombreux entrainements avec des humains, d'autres ordinateurs, et surtout lui-même.
https://fr.wikipedia.org/wiki/AlphaGo
https://fr.wikipedia.org/wiki/AlphaGo_Zero
https://fr.wikipedia.org/wiki/DeepMind
https://fr.wikipedia.org/wiki/Parcours_de_graphe
https://fr.wikipedia.org/wiki/Apprentissage_par_renforcement
"AlphaGo Zero - en octobre 2017 atteindra un niveau supérieur en jouant uniquement contre lui-même.
AlphaZero en décembre 2017 surpassera largement, toujours par auto-apprentissage, le niveau de tous
les joueurs humains et logiciels, non seulement au jeu de Go, mais aussi aux échecs et au Shōgi."
Rapport d'expérience AlphaZero - 5 Dec. 2017 (en anglais *pdf) : https://arxiv.org/pdf/1712.01815.pdf
-------------------------------------------------------------------------------------------------------------------------------
Rappel des faits:
1. Le championnat du monde d'échecs des ordinateurs (en anglais : World Computer Chess Championship, WCCC)
est une compétition annuelle entre les programmes d'échecs. Elle se tient souvent en parallèle avec les Olympiades informatiques,
une série de tournois entre ordinateurs pour d'autres jeux. La compétition est ouverte à tous les programmes d'échecs,
fondés sur des microprocesseurs, des superordinateurs ou du matériel dédié au jeu d'échecs.
https://fr.wikipedia.org/wiki/Championnat_du_monde_d%27%C3%A9checs_des_ordinateurs
2. Deep Junior (programme d'échecs - 3100 ELO). Il a gagné le World Microcomputer Chess Championship en 1997
et 2001, et le Championnat du monde d'échecs des ordinateurs en 2002, 2004, 2006, 2009 et 2013. En 2003 il dispute
un match en 6 parties face à Gary Kasparov (2850 ELO). Le match se termine à égalité 3-3. C'est peut-être
la dernière fois qu'un humain (en l'occurrence l'ancien champion du monde des échecs), tient tête a un super logiciel
spécifique d'échecs dans une compétition. Il arrive que certains champions font de performances ELO ponctuelles
très supérieures à leur classement, comme dans ce cas précis.
Le niveau ELO des ordinateurs/logiciels de compétition actuels est entres 3400-3200 ELO contre
2900-2700 ELO pour les champions humains. Le classement Elo est un système d’évaluation du niveau
de capacités relatif d’un joueur d’échecs ou de jeu de go, comme le QI en quelque sorte pour faire simple.
https://wikimonde.com/article/Junior_%28programme_d%27%C3%A9checs%29
https://fr.wikipedia.org/wiki/Classement_Elo
3. Le championnat du monde 13-16 Novembre 2017
Les 10 logiciels/ ordinateurs en compétition:
1. Stockfish
2. Komodo
3. Houdini
4. Shredder
5. Fire
6. Fizbo
7. Andscacs
8. Chiron
9. Gull
10. Booot
https://www.chess.com/article/view/chess-com-announces-computer-chess-championship
4. Classement final - 16 Novembre 2017 : Stockfish gagne la compétition
(ELO 3400 - pérformance réalise à ce tournoi 3526 ELO !)
1 Stockfish 051117 3400 3526 01 ½½ ½1 ½1 11 11 11 11 ½1 14.5/18
2 Houdini 6.02 3407 3444 10 ½½ ½½ 1½ 1½ 11 1½ 1½ 11 13.0/18
3 Komodo 1959.00b 3398 3422 ½½ ½½ ½1 ½½ ½1 ½½ 11 11 1½ 12.5/18
4 Fire 6.2 3300 3389 ½0 ½½ ½0 ½½ 1½ ½1 1½ 11 11 11.5/18
5 Andscacs 0.92 3240 3258 ½0 0½ ½½ ½½ ½½ ½½ ½½ ½½ ½½ 8.0/18
6 Fizbo 1.9 3262 3237 00 0½ ½0 0½ ½½ ½½ ½½ 11 ½½ 7.5/18 55.00
7 Deep Shredder 13 3291 3234 00 00 ½½ ½0 ½½ ½½ 11 ½½ ½½ 7.5/18 54.75
8 Chiron 4 3203 3159 00 0½ 00 0½ ½½ ½½ 00 ½0 11 5.5/18 39.50
9 Booot 6.2 3224 3157 00 0½ 00 00 ½½ 00 ½½ ½1 1½ 5.5/18 37.00
10 Gull 3 syz 3191 3112 ½0 00 0½ 00 ½½ ½½ ½½ 00 0½ 4.5/18
5. En Décembre 2017 AlphaGo Zero écrase littéralement le champion en titre des ordinateurs d'échecs Stockfish
par 28 victoires contre 72 parties nulles et aucune défaite. Toujours par auto-apprentissage ! d'après les spécialistes
et quelques informaticiens pointus, eux aussi surpris par la puissance et la vitesse "d'apprentissage" dAlphaGo Zero.
Google's AlphaZero Destroys Stockfish In 100-Game Match - Dec 6, 2017 - by Mike Klein
"Aujourd'hui, les échecs ont changé à tout jamais. Demain, peut-être le monde...
C'est le programme d'intelligence artificielle AlphaZero qui réalise l'exploit de battre
du premier coup le programme d'échecs le mieux classé du monde."
"Les développeurs d'AlphaZero (membres de DeepMind, une filiale de Google), ont lancé leur programme
sur une procédure d"apprentissage automatique", et plus exactement d'apprentissage par renforcement.
Pour faire simple, les développeurs n'ont pas "appris" le jeu à leur programme (au delà des règles de base).
Il ne possède ni répertoire d'ouverture, ni tableaux de finales, et apparemment, pas d'algorithme ultra-complexe."
"Petite précision : il n'a fallu que quatre heures à AlphaZero pour "apprendre" les échecs. Désolé, amis humains,
cette fois, c'est bel et bien terminé pour nous... "
(en) : https://www.chess.com/news/view/google-s-alphazero-destroys-stockfish-in-100-game-match
(fr): https://www.chess.com/fr/news/view/alphazero-le-programme-de-google-bat-stockfish-a-plates-coutures-4961


Images : chess.com
Dernière modification par alex20 (01/04/2018 07:18)
Hors ligne

Merci pour cette piqûre de rappel, depuis HAL on se doutait bien que cela arriverait un jour.
A jouer les apprentis sorcier (vouloir créer un surhomme pour l'aider à avancer) l'homme finira bien par se brûler les mains et le reste.

AMD Ryzen9 3900X / ASUS Rog Strix X570-E / B Quiet Dark Rock PRO4 / B Quiet 850W / B Quiet Dark Base Pro 900 rev.2
AMD Radeon RX 6800 XT 16GB GDDR6 / Corsair 32Go DDR4 3200 MHz / W10 pro-64-21H2 / MSFS
Hors ligne
Extrait du lien donné par Alex au message #7
https://www.sciencesetavenir.fr/high-tech/intelligence-artificielle/rapport-villani-l-ethique-en-intelligence-artificielle-un-sujet-a-part-entiere_122589
"Il est aujourd'hui impossible d'auditer une décision algorithmique de deep learning
Actuel titulaire de la chaire en sciences des données du Collège de France, le mathématicien Stéphane Mallat s'est employé à expliquer l'un des problèmes bien connus des algorithmes pourtant si efficaces de deep learning : l'impossibilité à expliquer pourquoi ils ont donné tel résultat, donc l'impossibilité à auditer une décision algorithmique. “Il y a là un grand mystère mathématique” qui fait l'objet d'une bonne part de la recherche. Ce "mystère" n'a rien d'anodin ou de périphérique : parvenir à reconstituer le cheminement logique d'un algorithme, trouver les critères sur lesquels il s'est appuyé, représente, à terme, un gage de transparence, de fiabilité et d'une plus grande confiance en des machines perçues encore comme des “boîtes noires”.
Mais c'est bien la mathématicienne américaine Cathy O'Neil qui s'est montrée la plus incisive et la moins angélique. Il faut dire qu'elle a vécu de près la folie algorithmique : cette ancienne d'Harvard travaillait dans le monde de la finance quand la crise financière de 2008 a éclaté. L'expérience, comme elle le revendique presque, lui a fait perdre pas mal d'illusion et réorienter ses réflexions. “Les algorithmes peuvent faire du mal, les algorithme peuvent mentir”
En bref on ne comprend pas vraiment le fonctionnement (Ou plutot le"cheminement algorithmique") de cette nouvelle generation d'IA...
La notion d'algorithme semble d'ailleurs deja depassée...on est bien la face a une nouvelle forme d'intelligence...qui nous depasse, par sa puissance et sa logique interne...
A partir de la comment en garder le controle ?
Vraiment effrayant...
Dernière modification par Wind_D4ncer (01/04/2018 11:54)
Ils ne savaient pas que c'etait impossible... Alors ils l'ont fait...
Hors ligne
Bonjour à tous,
Si vous me permettez une derrière remarque (et lien) sur mon dernier sujet AlphaGo Zero et le jeu des échecs:
AlphaZero, l'intelligence artificielle créée par Google DeepMind, a battu le programme champion du monde d'échecs
Stockfish 8 après s'être auto-enseigné le jeu d'échecs pendant quatre heures. Le point sur cette révolution.
https://www.europe-echecs.com/art/alphazero-ecrase-stockfish-8-7203.html
« C'est une performance remarquable, même si nous aurions dû nous y attendre après AlphaGo », a déclaré
le 12e champion du monde d'échecs Garry Kasparov. « Nous avons toujours supposé que les échecs
nécessitaient trop de connaissances empiriques pour qu'une machine joue aussi bien à partir de zéro, sans
aucune connaissance humaine. »
« Sans aucune connaissance du domaine à l'exception des règles du jeu, AlphaZero a atteint en 24 heures
un niveau de jeu surhumain aux Échecs, Shogi et Go. », ont déclaré les auteurs de l'article, dont le fondateur
de DeepMind, Demis Hassabis. >>
<<Demis Hassabis est né à Londres en juillet 1976 et a rapidement montré une habileté pour les jeux de société,
en particulier les échecs. À l'âge de 13 ans, Hassabis a été le deuxième joueur le mieux classé au monde
(moins de 14 ans)>>
Hors ligne
Merci pour ce nouveau lien Alex
Ce qui me frappe le plus dans cet article:
"son approche d'apprentissage automatique ne reçoit aucune contribution humaine en dehors des règles de base. Quant au reste, il fonctionne en jouant encore et encore avec des connaissances auto-renforcées. Le résultat, selon DeepMind, est qu'Alphazero a adopté une « approche sans doute plus humaine » pour la recherche des coups, traitant environ 80 000 positions par seconde par rapport aux 70 millions de Stockfish 8."
Il traite donc mille fois moins de données...Il choisit donc les plus appropriées .....sans traiter la totalité ! 
...Une forme d'intuition ? Difficile a dire...
Par contre la compararaison des puissances de calcul des 2 machines me semble impossible...
Concernant la "methode de monte carlo"
https://fr.wikipedia.org/wiki/Algorithme_de_Monte-Carlo
"En algorithmique, un algorithme de Monte-Carlo est un algorithme randomisé dont le temps d'exécution est déterministe, mais dont le résultat peut être incorrect avec une certaine probabilité (généralement minime). Autrement dit un algorithme de Monte-Carlo est un algorithme qui utilise une source de hasard, dont le temps de calcul est connu dès le départ (pas de surprise sur la durée du calcul), cependant dont la sortie peut ne pas être la réponse au problème posé, mais c'est un cas très rare. L’intérêt de tels algorithmes est d'avoir une probabilité d'échec faible et d'être rapide."
@+
Dernière modification par Wind_D4ncer (02/04/2018 11:31)
Ils ne savaient pas que c'etait impossible... Alors ils l'ont fait...
Hors ligne
Sujet très vaste l'"Algorithme de Monte-Carlo"..
Merci pour tous tes messages, remarques et liens! Wind_D4ncer 
C'est vrai qu''Alpha zéro" n'a reçu aucune "programmation" préalable ou "implenté" de bibliothèques
et tables d'ouverture, finales etc. Il est devenu un "zombie" informatique presque incontrôlable suite
à son propre auto-apprentissage. Par comparaison un logiciel comme Deep junior v.13.8 il a une Database
de 1.5 millions parties mémorisées et une extension de 200 millions positions analysées.
Anecdote : le futur championnat du monde des ordinateurs 2018 est peut-être déjà gagné d'avance par Alphazero
et son algorithme, largement supérieur à "ses" concurrents actuels. Comment faire savoir au monde que...
les autres logiciels/ordinateurs d'échecs sont ( déjà obsolètes?) ou pas?
Dernière modification par alex20 (03/04/2018 00:45)
Hors ligne
Wind_D4ncer ! merci infiniment pour ce lien, je conseille à tout le monde de le voir ou le revoir !
Il s'agit de l'Atlas Robot de Boston Dynamics !
https://www.cnbc.com/2017/11/16/boston-dynamics-atlas-robot-can-now-do-a-backflip.html
Vidéo Boston Dynamics 2017: https://www.youtube.com/watch?v=fRj34o4hN4I
------------------------------------------------------------------------------------------------------------
Il sont aussi les concepteurs du Big Dog en 2008 déjà impressionnant à l'époque (surtout entre 1m25s et 2m):
https://www.youtube.com/watch?v=W1czBcnX1Ww
------------------------------------------------------------------------------------------------------------
Et une autre vidéo explicative avec un robot MIT (Massachusetts Institute of Technology ) :
https://www.youtube.com/watch?v=_luhn7TLfWU
Dernière modification par alex20 (03/04/2018 01:08)
Hors ligne
Wind_D4ncer ! merci infiniment pour ce lien, je conseille à tout le monde de le voir ou le revoir !
Il s'agit de l'Atlas Robot de Boston Dynamics !https://www.cnbc.com/2017/11/16/boston-dynamics-atlas-robot-can-now-do-a-backflip.html
Vidéo Boston Dynamics 2017: https://www.youtube.com/watch?v=fRj34o4hN4I
------------------------------------------------------------------------------------------------------------
Il sont aussi les concepteurs du Big Dog en 2008 déjà impressionnant à l'époque (surtout entre 1m25s et 2m):
https://www.youtube.com/watch?v=W1czBcnX1Ww
------------------------------------------------------------------------------------------------------------
Et une autre vidéo explicative avec un robot MIT (Massachusetts Institute of Technology ) :
https://www.youtube.com/watch?v=_luhn7TLfWU
Pour le Boston dynamics, impressionnant, à un moment il se " rattrape " comme un être humain, on dirait qu'il a des attitudes humaines, mais il pourra aller dans des endroits inaccessibles pour nous
pour le robot MIT, ils peuvent servir à beaucoup de choses, ce qui importe c'est que ce soit toujours l'être humain qui contrôle; à partir du moment où c'est la machine qui décide, c'est fichu , le processus est enclenché...
dire que j'ai vu dans un reportage des chercheurs qui " cherchent ", justement, à faire des robots qui se rapprochent du même mode de pensée que celui des humains  : ils y arriveront , tout va tellement vite !
: ils y arriveront , tout va tellement vite !
Hors ligne
Oui ils y arriveront...ce n'est qu'une question de temps....
Quelques liens sur l'algorithmique d'Alpha Zero....
https://medium.com/applied-data-science/alphago-zero-explained-in-one-diagram-365f5abf67e0
Lien direct vers le diagramme:
https://applied-data.science/static/main/res/alpha_go_zero_cheat_sheet.png
Un "How to" programmer son propre Alpha Zero en Python avec "Keras"
https://medium.com/applied-data-science/how-to-build-your-own-alphazero-ai-using-python-and-keras-7f664945c188
https://en.wikipedia.org/wiki/Keras
D'aprés cet article l'algorithme de Alpha zero est "ridiculously elegant"
What makes it extraordinary is that a lot of the ideas in the paper are actually far less complex than previous versions. At its heart, lies the following beautifully simple mantra for learning:
- Mentally play through possible future scenarios, giving priority to promising paths, whilst also considering how others are most likely to react to your actions and continuing to explore the unknown.
- After reaching a state that is unfamiliar, evaluate how favourable you believe the position to be and cascade the score back through previous positions in the mental pathway that led to this point.
- After you’ve finished thinking about future possibilities, take the action that you’ve explored the most.
- At the end of the game, go back and evaluate where you misjudged the value of the future positions and update your understanding accordingly.
Doesn’t that sound a lot like how you learn to play games?
Ils ne savaient pas que c'etait impossible... Alors ils l'ont fait...
Hors ligne
Encore merci Wind_D4ncer pour ces liens !
Hors ligne
Le réseau "neuronal" d'AlphaZero, qu'on peut schématiser comme suit :
https://www.chess.com/fr/article/view/quy-a-t-il-dans-le-cerveau-echiqueen-dalphazero
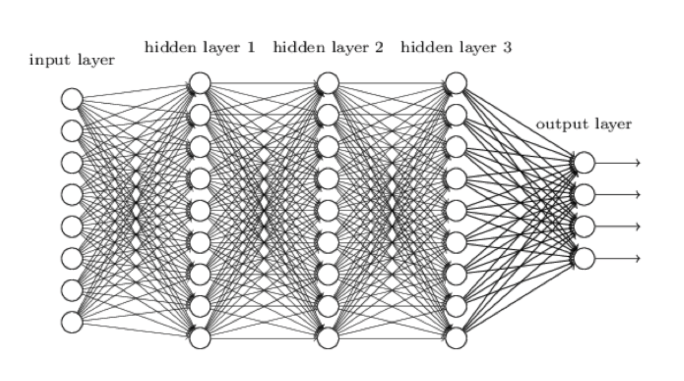
------------------------------------------------------------------------------------------------------------------------
"Le matériel qui permet de faire tourner AlphaZero
Sans surprise, le réseau neuronal d'AlphaZero tourne sur un matériel ultra-spécialisé :
Le Tensor Processing Unit (TPU) de Google. AlphaZero a utilisé 5000 TPUs de première génération
pour jouer contre lui-même, ce qui a permis de "former" son réseau, et 64 TPU de seconde générations
pour l'entraînement proprement dit. Il s'agit là d'une puissance informatique formidable. Pour simplement
jouer aux échecs, il n'a besoin que de quatre TPUs !
Pourquoi ne pas avoir utilisé les 5060 autres TPUs ? Probablement pour prouver qu'AlphaZero n'a pas besoin
d'énormément de matériel pour fonctionner effectivement."

Un Tensor Processing Unit (TPU)
Dernière modification par alex20 (05/04/2018 00:56)
Hors ligne

Quelle définition donnons-nous à "l'intelligence" pour considérer les IA comme étant...intelligente? De mon point de vu, si cela se résume à juste résoudre des problèmes certes très complexes, c'est très insuffisant. La capacité d'auto-apprentissage alors? La aussi elle n'aboutit qu'à mieux résoudre des problèmes. J'entends par là que ça ne sort pas du contexte car cet auto-apprentissage n'est pas un enrichissement de l'expérience.
i7 12700F - Gigabyte Z690 UD - RTX 5070Ti - 64Go RAM DDR4 4000 - W11 64bits - WINWING F16EX - VPC MongoosT-50CM3 - Pro Flight Switch Panel - Pro Flight Radio Panel - Pro Flight Multi Panel - TQ6+ - 4 x FIP - Thrustmaster TPR - TrackIR 5 - 3x MFD avec 3 écrans HDMI 8" - VPC Controle Panel - VPC Rotor TCS Plus Base -VPC Hawk 60 Collective Grip - StreamDeck - Ecran 55 pouces"
Hors ligne
Puisqu'on parle des TPU developpés par Google, il faut aussi mentionner le site TensorFlow qui regroupe les biblothèques open source de machine learning développées par Google et mises à disposition de la communauté
https://www.tensorflow.org/
Dernière modification par ydelta (05/04/2018 13:25)
PC: i9 9900K @5.2 Ghz - Gigabyte GEForce RTX 4080 OC 16 Go - Asus Z390 Pro Gaming - 32Go de RAM DDR4 3200
Portable: MSI Raider 18 HX - i9 14900HX RTX 4080 12Go 4K 18" display 240hz - 64Go DDR5 5200 - 3To M2 SSD
Hors ligne
Quelle définition donnons-nous à "l'intelligence" pour considérer les IA comme étant...intelligente? De mon point de vu, si cela se résume à juste résoudre des problèmes certes très complexes, c'est très insuffisant. La capacité d'auto-apprentissage alors? La aussi elle n'aboutit qu'à mieux résoudre des problèmes. J'entends par là que ça ne sort pas du contexte car cet auto-apprentissage n'est pas un enrichissement de l'expérience.
Bonjour Usul, bonjour à tous,
"L'apprentissage par renforcement fait référence à une classe de problèmes d'apprentissage automatique, dont le but
est d'apprendre, à partir d'expériences, ce qu'il convient de faire en différentes situations, de façon à optimiser
une récompense quantitative au cours du temps."
Lien que j'ai donné plus haut : procédure d "apprentissage automatique,-> apprentissage par renforcement.
https://fr.wikipedia.org/wiki/Apprentissage_par_renforcement
Méthode et principe (entre autres) appliqué par les développeurs d'AlphaZero :
"Les développeurs d'AlphaZero (membres de DeepMind, une filiale de Google), ont lancé leur programme
sur une procédure d"apprentissage automatique", et plus exactement d'apprentissage par renforcement. "
https://www.chess.com/fr/news/view/alphazero-le-programme-de-google-bat-stockfish-a-plates-coutures-4961
Dernière modification par alex20 (06/04/2018 00:37)
Hors ligne
Puisqu'on parle des TPU developpés par Google, il faut aussi mentionner le site TensorFlow qui regroupe les biblothèques open source de machine learning développées par Google et mises à disposition de la communauté
https://www.tensorflow.org/
Merci pour l'info et le lien Ydelta !
Hors ligne
